Today we will build small API service based on Rust programming language with VueJS frontend app.
Backend: https://github.com/mg-rust/rustjobs.cc
Frontend: https://github.com/mg-javascript/rustjobs.cc_client
Features
Which features we will implement within our API?
How about this:
- List of Jobs
- Adding new Job
- Job page
Project setup: Rust
Let’s install Rust first - https://www.rust-lang.org, you can find a lot of manuals and additional information about Rust on the internet.
Just run simple command, and restart your terminal session.
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
Project setup: Cargo
What is Cargo? Cargo is Rust’s build system and package manager.
You can read more about Cargo here: https://doc.rust-lang.org/book/ch01-03-hello-cargo.html
As a first step - check Cargo version:
cargo --version
cargo 1.43.0 (2cbe9048e 2020-05-03)
Next - let’s generate new app:
cargo new rust-jobs-api --bin && cd rust-jobs-api
If you want to compile and run project, just enter:
cargo run
Project setup: Cargo.toml
The Cargo.toml file for each package is called its manifest. Every manifest file consists of the following sections.
Example section from https://doc.rust-lang.org:
[package]
name = "hello_world" # the name of the package
version = "0.1.0" # the current version, obeying semver
authors = ["Alice <a@example.com>", "Bob <b@example.com>"]
Let’s add dependencies to our file, we’ll build our API with Actix framework - https://actix.rs.
[package]
name = "rustjobs"
version = "0.0.3"
authors = ["Marat Galiev <kazanlug@gmail.com>"]
edition = "2018"
[dependencies]
actix-web = "2.0"
actix-rt = "1.0"
actix-cors = "0.2.0"
chrono = { version = "0.4", features = ["serde"] }
dotenv = "0.11"
bigdecimal = "0.0.14"
diesel = { version = "1.4", features = ["postgres", "r2d2", "uuid", "chrono"] }
diesel_migrations = "1.4"
env_logger = "0.6"
lazy_static = "1.4"
log = "0.4"
serde = "1.0"
serde_json = "1.0"
r2d2 = "0.8"
uuid = { version = "0.6", features = ["serde", "v4"] }
Building backend: database setup
We will use Diesel ORM - http://diesel.rs, for DB migrations.
Let’s install diesel_cli and add dependencies into Cargo.toml file and setup Diesel:
# setup DB
$ diesel setup
# generating migration
$ diesel migration generate create_jobs
# run migrations (see next chapter)
$ diesel migration run
Building backend: database connection
Diesel migrations are simple directories with two sql files up.sql and down.sql, for migrate and rollback your SQL code.
Let’s define our schema in SQL based migration.
CREATE TABLE jobs (
id SERIAL PRIMARY KEY,
title VARCHAR(255) NOT NULL,
description TEXT NOT NULL,
salary INT,
job_type character varying(255) NOT NULL,
is_remote boolean DEFAULT FALSE,
currency character varying(255) NOT NULL,
apply_url character varying(255),
job_city character varying(255) NOT NULL,
job_email character varying(255) NOT NULL,
company character varying(255) NOT NULL,
company_twitter character varying(255),
company_website character varying(255) NOT NULL,
company_logo character varying(255),
slug character varying(255),
created_at timestamp,
updated_at timestamp
);
Cool. Next file (let’s say db.rs) - was build for connection purposes to PostgreSQL server.
So, here we are defining Pool and Connection.
Our connection string will be stored in .env file or environment variable called DATABASE_URL.
use crate::error_handler::CustomError;
use diesel::pg::PgConnection;
use diesel::r2d2::ConnectionManager;
use lazy_static::lazy_static;
use r2d2;
use std::env;
type Pool = r2d2::Pool<ConnectionManager<PgConnection>>;
pub type DbConnection = r2d2::PooledConnection<ConnectionManager<PgConnection>>;
embed_migrations!();
lazy_static! {
static ref POOL: Pool = {
let db_url = env::var("DATABASE_URL").expect("Database url not set");
let manager = ConnectionManager::<PgConnection>::new(db_url);
Pool::new(manager).expect("Failed to create db pool")
};
}
pub fn init() {
lazy_static::initialize(&POOL);
let conn = connection().expect("Failed to get db connection");
embedded_migrations::run(&conn).unwrap();
}
pub fn connection() -> Result<DbConnection, CustomError> {
POOL.get()
.map_err(|e| CustomError::new(500, format!("Failed getting db connection: {}", e)))
}
After running migrations with Diesel, you will see schema.rs file with generated schema for your table.
table! {
jobs (id) {
id -> Int4,
title -> Varchar,
description -> Text,
salary -> Nullable<Int4>,
job_type -> Varchar,
is_remote -> Nullable<Bool>,
currency -> Varchar,
apply_url -> Nullable<Varchar>,
job_city -> Varchar,
job_email -> Nullable<Varchar>,
company -> Varchar,
company_twitter -> Nullable<Varchar>,
company_website -> Varchar,
company_logo -> Nullable<Varchar>,
slug -> Nullable<Varchar>,
created_at -> Nullable<Timestamp>,
updated_at -> Nullable<Timestamp>,
}
}
Building backend: Job model
Let’s describe routes in our app.
Simple as 1+1 - three endpoints, one GET for all jobs, one GET for a specific job and one POST request for new job.
use crate::jobs::{Job, Jobs};
use crate::error_handler::CustomError;
use actix_web::{get, post, web, HttpResponse};
#[get("/jobs")]
async fn find_all() -> Result<HttpResponse, CustomError> {
let jobs = Jobs::find_all()?;
Ok(HttpResponse::Ok().json(jobs))
}
#[get("/jobs/{id}")]
async fn find(id: web::Path<i32>) -> Result<HttpResponse, CustomError> {
let job = Jobs::find(id.into_inner())?;
Ok(HttpResponse::Ok().json(job))
}
#[post("/jobs")]
async fn create(job: web::Json<Job>) -> Result<HttpResponse, CustomError> {
let job = Jobs::create(job.into_inner())?;
Ok(HttpResponse::Ok().json(job))
}
pub fn init_routes(configuration: &mut web::ServiceConfig) {
configuration.service(find_all);
configuration.service(find);
configuration.service(create);
}
Next - Job and Jobs structs for describing json output.
Also let’s add some search methods, here we are doing requests to the DB through database library from previous steps.
use crate::db;
use crate::error_handler::CustomError;
use crate::schema::jobs;
use diesel::prelude::*;
use serde::{Deserialize, Serialize};
use chrono::prelude::{Utc};
use std::fmt;
#[derive(Serialize, Deserialize, AsChangeset, Insertable)]
#[table_name = "jobs"]
pub struct Job {
pub title: String,
pub description: String,
pub salary: Option<i32>,
pub job_type: String,
pub is_remote: Option<bool>,
pub currency: String,
pub apply_url: Option<String>,
pub job_city: String,
pub job_email: Option<String>,
pub company: String,
pub company_twitter: Option<String>,
pub company_website: String,
pub company_logo: Option<String>,
pub slug: Option<String>,
pub created_at: Option<chrono::NaiveDateTime>,
pub updated_at: Option<chrono::NaiveDateTime>,
}
#[derive(Serialize, Deserialize, Queryable, Insertable)]
#[table_name = "jobs"]
pub struct Jobs {
pub id: i32,
pub title: String,
pub description: String,
pub salary: Option<i32>,
pub job_type: String,
pub is_remote: Option<bool>,
pub currency: String,
pub apply_url: Option<String>,
pub job_city: String,
pub job_email: Option<String>,
pub company: String,
pub company_twitter: Option<String>,
pub company_website: String,
pub company_logo: Option<String>,
pub slug: Option<String>,
pub created_at: Option<chrono::NaiveDateTime>,
pub updated_at: Option<chrono::NaiveDateTime>,
}
// DEBUG PURPOSES
impl fmt::Debug for Job {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.debug_struct("Job")
.field("created_at", &self.created_at)
.finish()
}
}
impl Jobs {
pub fn find_all() -> Result<Vec<Self>, CustomError> {
let conn = db::connection()?;
let jobs = jobs::table.select(jobs::all_columns).order(jobs::id.desc()).load::<Jobs>(&conn)?;
Ok(jobs)
}
pub fn find(id: i32) -> Result<Self, CustomError> {
let conn = db::connection()?;
let job = jobs::table.filter(jobs::id.eq(id)).first(&conn)?;
Ok(job)
}
pub fn create(job: Job) -> Result<Self, CustomError> {
let now = Utc::now().naive_utc();
let job = Job {
created_at: Some(now),
updated_at: Some(now),
..job
};
let conn = db::connection()?;
let job = Job::from(job);
let job = diesel::insert_into(jobs::table)
.values(job)
.get_result(&conn)?;
Ok(job)
}
}
impl Job {
fn from(job: Job) -> Job {
Job {
title: job.title,
description: job.description,
salary: job.salary,
job_type: job.job_type,
is_remote: job.is_remote,
currency: job.currency,
apply_url: job.apply_url,
job_city: job.job_city,
job_email: job.job_email,
company: job.company,
company_twitter: job.company_twitter,
company_website: job.company_website,
company_logo: job.company_logo,
slug: job.slug,
created_at: job.created_at,
updated_at: job.updated_at
}
}
}
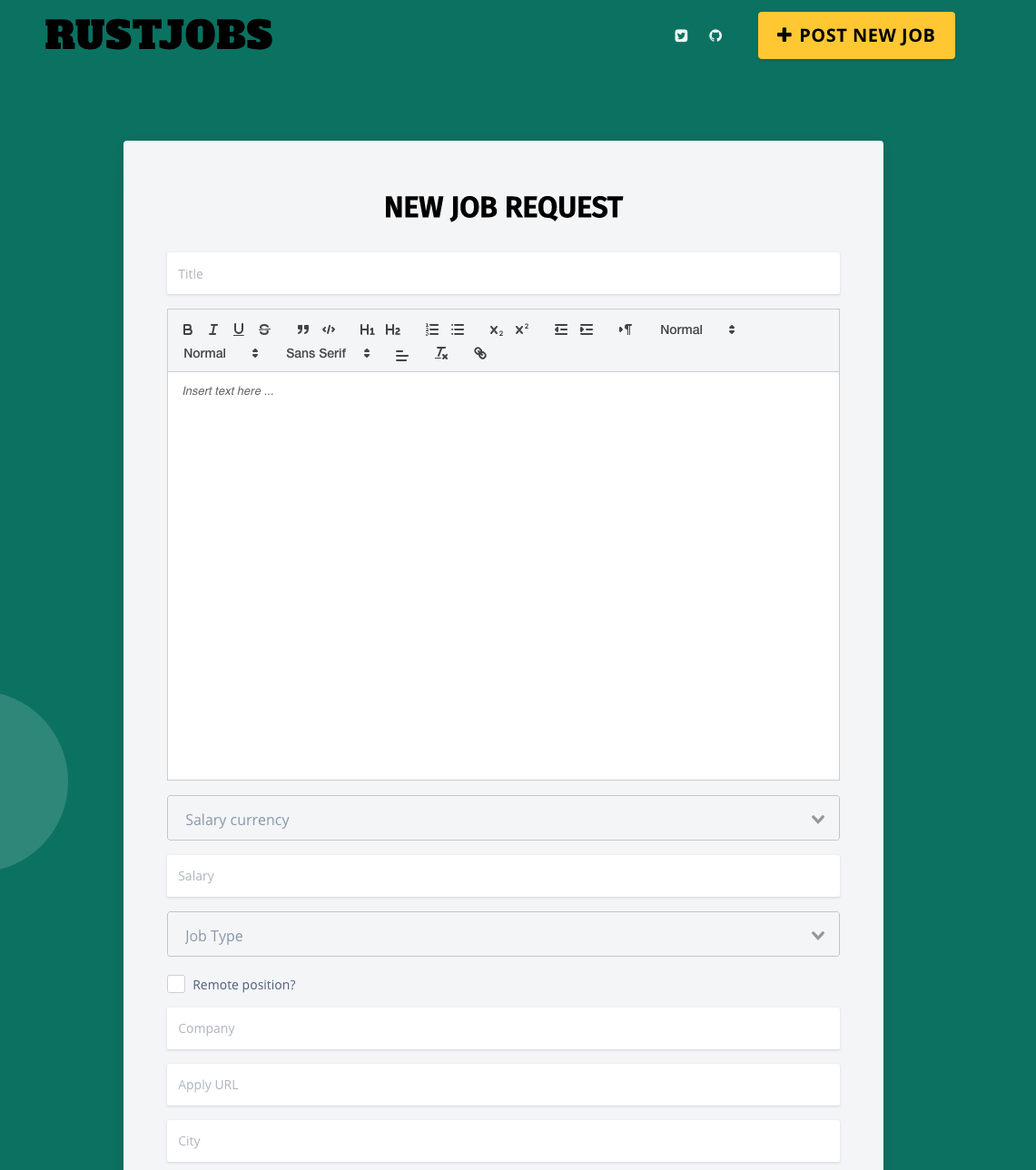
Screenshots
Main page:

Adding new job page:
Final
All code looks pretty simple and logically clear, feel free to checkout github repos for backend code and frontend app.
Stay tuned!