Apache Kafka
What is Apache Kafka?
Let’s check official Kafka desсription:
Apache Kafka is a distributed streaming platform.
Again. Kafka is not a message bus. It is a distributed streaming platform.
How it works?
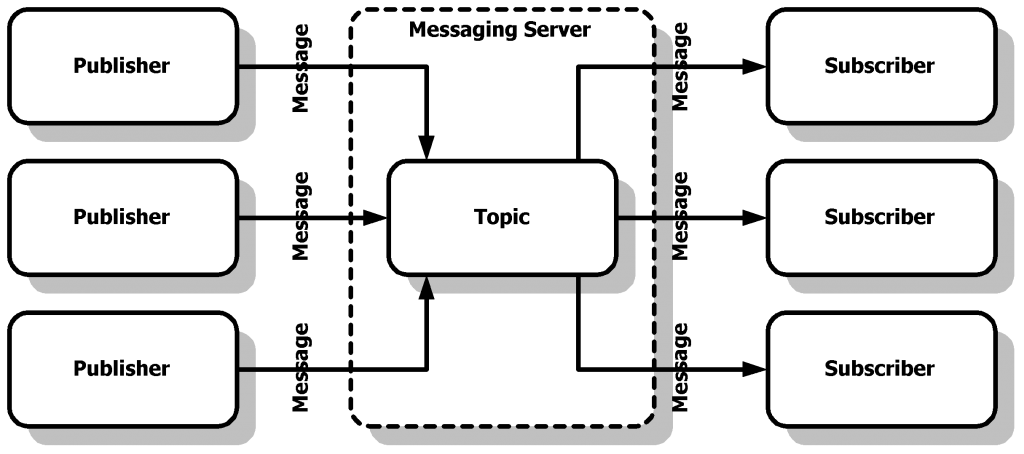
What Kafka can do/ can’t do:
1) Kafka can send data with just only one pattern: producer - consumer
2) Kafka store messages after delivery (7 days by default)
3) Performance - about 100k in second (not very relevant but 20k in RabbitMQ for example)
4) Clustering
5) Kafka can save messages to disk
6) Availability - partitions/replication
7) Exactly-once delivery

Usage
As I said before - Kafka is a distributed system that runs in a cluster. Each node in the cluster is called a Kafka broker. Broker is a single Kafka process that operates in a cluster.
For example you want to track users activity in your app. Searches, clicks, page views etc - you can arrange them to different topics and then get this info for statistics services for example.
Another popular case - log rotating or event-based apps architecture layer.
Install and run Kafka and Zookeeper
brew cask install homebrew/cask-versions/java8
brew install kafka
brew services start zookeeper
brew services start kafka
Of course you can use docker images from here for example: https://hub.docker.com/r/wurstmeister/kafka/
Let’s try to test local Kafka installation:
A topic is a category or feed name to which records are published.
Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
Let’s try to create first test topic:
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Created topic "test".
Now we will initialize the Kafka producer console, which will listen to localhost at port 9092 at topic test:
kafka-console-producer --broker-list localhost:9092 --topic test
>send 1 message
>send 2 message
>works!
Now we will initialize the Kafka consumer console, which will listen to bootstrap server localhost at port 9092 at topic test from beginning:
kafka-console-consumer --bootstrap-server localhost:9092 --topic test --from-beginning
send 1 message
send 2 message
works!
Super simple!
Populare ruby/rails solutions to run.
For ruby and rails you can choose from different gems/solutions to run your and communicate with Kafka.
Karafka + Waterdrop
https://github.com/karafka/karafka
https://github.com/karafka/waterdrop
Add gems:
gem 'waterdrop'
gem 'karafka'
Setup your connection:
WaterDrop.setup do |config|
config.kafka.seed_brokers = %w[kafka://localhost:9092]
end
Send your message:
WaterDrop::SyncProducer.call('event message', topic: 'events-topic-internal')
Ruby kafka
https://github.com/zendesk/ruby-kafka
require 'kafka'
class KafkaClient
def self.client
@client ||= Kafka.new(seed_brokers: ENV['CONNECTION_STRING'])
end
def self.produce(data, topic:)
client.producer.produce(data, topic: topic)
client.producer.deliver_messages
end
Call it!
KafkaClient.produce(my_message_data, topic: 'very_useful_messages')
Delifery boy
Another simple way to publish messages to Kafka from Ruby applications.
https://github.com/zendesk/delivery_boy
# app/controllers/jobs_controller.rb
class JobsController < ApplicationController
def show
@job = Job.find(params[:id])
event_for_kafka = {
job_id: @job.id,
ip_address: request.remote_ip,
timestamp: Time.now,
user_id: current_user
}
# DeliveryBoy.deliver(event.to_json, topic: "job-views") - BLOCKS THE SERVER PROCESS
# Calling `deliver_async` will enqueue the message in an asynchronous
# Kafka producer that will periodically deliver all pending messages.
DeliveryBoy.deliver_async(event.to_json, topic: "job-views")
end
end
Phobos
Simplifying Kafka for ruby apps - https://github.com/phobos/phobos.
Phobos is a micro framework and library for applications dealing with Apache Kafka.
Install Phobos:
gem 'phobos'
Add configuration:
phobos init
create config/phobos.yml
create phobos_boot.rb
Add Producer:
class JobProducer
include Phobos::Producer
end
And use it:
JobProducer.producer.publish('job-topic', 'job-message-payload', 'partition and message key')
Add handler (Consumer)
class JobHandler
include Phobos::Handler
def consume(payload, metadata)
# payload - This is the content of your Kafka message, Phobos does not attempt to
# parse this content, it is delivered raw to you
# metadata - A hash with useful information about this event, it contains: key,
# partition, offset, retry_count, topic, group_id, and listener_id
# your code here
end
end
Configure your Phobos installation:
config/phobos.yml
listeners:
- handler: JobHandler
topic: job-topic
group_id: job-1
Run Phobos:
phobos start
Rafka
Another insteresting project:
https://github.com/skroutz/rafka
Super useful article and services for systemd implementation on this link:
https://engineering.skroutz.gr/blog/kafka-rails-integration/
Conclusion
Thats all. As you can see, Kafka can be super useful on different part of your apps.
Just try to choose there parts correctly
Stay tuned.